
If agents end up writing most of our code, the role of engineers will shift, where our roles have never been “just” about writing code. We define intent and constraints, orchestrate agent work, verify results, and stay accountable for the outcomes.
But AI can already generate code at scale. That means we need to redefine the SDLC around the artifacts that matter in an agentic workflow. Not just the code itself, but the context and reasoning that produced it, and the evidence showing it delivered the right outcomes. So we can stay accountable.
My working take is that agent conversations should be treated like build artifacts: linked to commits with stable identifiers, and paired with verification evidence so changes remain reviewable and auditable.
One of the real challenges is whether we can turn intent into verifiable, reconstructable value that holds up in review, audits, incident response, and governance.
So the question becomes:
If AI agents write our code, how can we make sure we’re actually delivering that value, and that we can prove it later?
In practice, that means getting disciplined about:
- providing the right context (intent, constraints, risk)
- verifying the outcome (tests, checks, benchmarks, approvals)
- preserving the evidence trail so we can reconstruct it later (review, incident, audit)
Today I’d like to dive into that question.
Context is the missing artifact
When you look at a line in Git blame, you usually want the reason behind it, not a person.
That context exists, but it’s spread out:
- Jira tickets, specs, PR comments
- chat and meeting notes
- IDE or vendor agent transcripts
- etc.
Foundation Capital calls this idea a “context graph”: decision traces over time that make decision history searchable. Cognition makes a similar point for software: we’re context constrained, and throwing context away is costly.
The ecosystem is already moving this way. Tools like Entire treat agent sessions as first-class development artifacts, capturing and indexing them alongside commits so context and reasoning become searchable. Their approach, “every commit tells a story”, recognizes that the story matters as much as the code.
Agent Trace in one paragraph
Agent Trace is an open spec that links code changes (down to file and line ranges) to the conversation that produced them. It is storage-agnostic and has extensible metadata.
The spec’s goals: interoperability (any compliant tool can read/write attribution), granularity (file and line-level attribution), extensibility (custom metadata without breaking compatibility), and human & agent readability (no special tooling required). It explicitly does not track code ownership, training data provenance, or quality assessment—it’s purely about attribution.
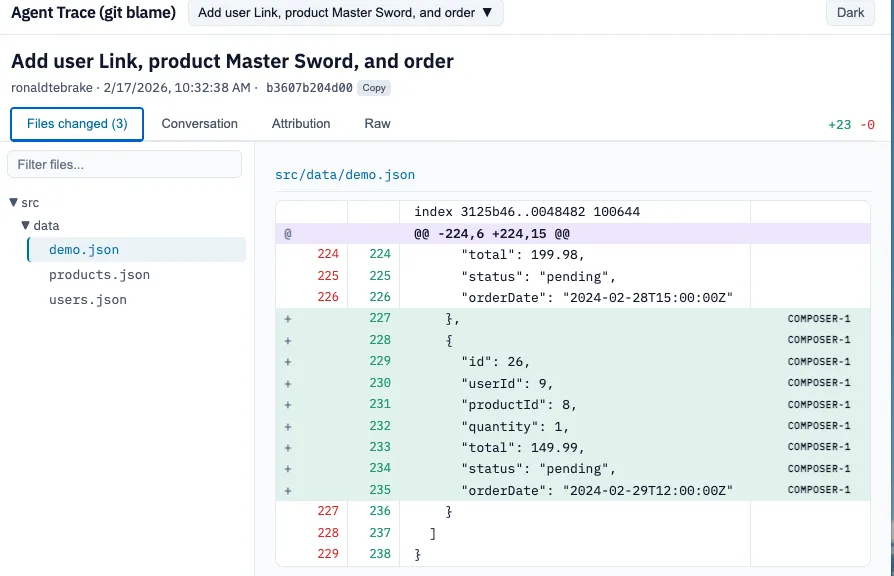
My POC: one trace per commit, stored as git notes
I store a trace record as git notes (example: refs/notes/agent-trace). That keeps normal history clean but still attaches trace data to a revision.
A simplified example:
{
"vcs": { "type": "git", "revision": "82d2b3c..." },
"files": [
{
"path": "src/data/demo.json",
"conversations": [
{
"url": "file:///.../agent-transcripts/<id>.txt",
"ranges": [{ "start_line": 243, "end_line": 251 }]
}
]
}
],
"metadata": { "conversation_id": "<id>" }
}Here’s a demo of the POC in action:
You can see how I’m able to trace the entire conversation I had in my IDE. The steps the agent took, the tool calls it performed and the outcome. We can even see what model was used for what line. Giving me all the context I need.
Why it matters: autonomy needs an evidence layer
Git blame isn’t going away. Most people use it to find issue → PR → commit → when/who and the context for that specific line, and that stays true with agents.
What can change is what that commit points you to.
If agents write most of the code, commits and PRs become decision boundaries:
- a place to gate risk
- a place to attach evidence
- a stable anchor for rollback and incident response
With per-commit traces, you get a simple but powerful workflow:
From a commit (or even a line range), you can jump to the context that produced it.
But the real goal is bigger than “prompt tracking”. It is the relationship between:
- intent (ticket/spec/ADR)
- code (the diff)
- verification (tests, checks, approvals, benchmarks)
- outcomes (deploy/incident signals, later)
That could enable some practical upgrades.
1) Review becomes “intent inspection + verification”
Instead of guessing intent from diffs, reviewers can jump to the reasoning behind the risky parts and then verify it with independent evidence (tests, checks, benchmarks).
Good rule of thumb: the trace explains intent. Verification proves it.
2) CI becomes intent-aware (add, don’t replace)
We currently see a lot of usage of CODEOWNERS, which is path-based, but risk isn’t.
With traces plus basic risk scoring, review can be routed by “what is this trying to do?” not only “which folder changed?”
Think: owners for auth flows, data migrations, API contracts, security hardening.
This pairs well with “agentic codeowners” ideas: low-risk PRs move faster, high-risk PRs get the right humans, and break-glass actions are explicit.
Trace metadata can help you add targeted tests when intent suggests risk (auth, permissions, migrations, API changes).
3) Observability gets closer to the SDLC
There’s a proposal to represent Agent Trace in OpenTelemetry, treating code attribution as telemetry you can correlate with builds, deploys, incidents, and rollbacks.
This is interesting because it turns traces into something you can query like other operational data: “which agent runs produced code that later regressed performance?” or “what changed before this incident?”
I hope this becomes a standard
We don’t need another tool to do this
- agents emit traces in a common format
- teams store them however they want (notes, sidecars, a store)
- GitHub and GitLab surface “explain this change” where we already work
That’s how everyone benefits, without extra vendor-specific CLIs.
What I’m curious about
Right now, traces feel like documentation and auditable insights—useful for understanding “why” after the fact. But will they ever be more than that?
I’m curious about your experience: have you tried capturing agent context alongside commits? What are you seeing in practice? And do you think traces can become actionable inputs for automation—routing, approvals, gates—or will they always be retrospective documentation?
